Funciones: Introducción (1ºBach)
De Wikipedia
| Enlaces internos | Para repasar o ampliar | Enlaces externos |
| Indice Descartes Manual Casio | WIRIS Geogebra Calculadoras |
Tabla de contenidos |
Introducción
- El análisis matemático es una rama de las matemáticas que estudia los números reales, los complejos y las funciones entre esos conjuntos. Se empieza a desarrollar a partir de de la formulación rigurosa de límite y estudia conceptos como la continuidad, la integración y la derivación.
- El cálculo infinitesimal o simplemete Cálculo es una rama del análisis matemático que se divide en dos áreas: cálculo diferencial y cálculo integral.
- El cálculo diferencial es una parte del análisis matemático que consiste en el estudio de cómo cambian las funciones cuando sus variables cambian. El principal objeto de estudio en el cálculo diferencial es la derivada.
- El cálculo diferencial es una parte del análisis matemático que consiste en el estudio de las integrales. Básicamente, una integral es una generalización de la suma de infinitos sumandos, infinitamente pequeños.
Una de las diferencias entre el álgebra y el análisis es que en este segundo recurre a construcciones que involucran sucesiones de un número infinito de elementos, mientras que álgebra usualmente es finitista.
- Introducción al cálculo diferencial.
Sin duda Newton es el autor del primer paso de la carrera espacial. Las Leyes descubiertas por él son las que han permitido al hombre poner un pie en la Luna o enviar naves a Marte y Venus, explorar los planetas exteriores: Júpiter, Saturno, Neptuno y Urano. Su modelo de telescopio ha permitido ver más lejos en cielo. Sin duda los astrónomos le deben mucho a Newton. Pero los matemáticos, y de paso el resto de los científicos, le deben tanto o más. Él junto a Leibniz, aunque sería mejor decir al mismo tiempo que Leibniz, son los descubridores de la más potente y maravillosa herramienta matemática: el Cálculo. Newton tuvo en vida un prestigio y un reconocimiento social aún mayor que el que pudo tener Einstein en nuestro siglo. Como los reyes y muy pocos nobles fue enterrado en la abadía de Westminster. Leibniz murió sólo y abandonado por todos. A su entierro en Hannover sólo asistió su criado. Hoy los dos comparten por igual la gloria de ser los padres de las dos herramientas más potentes del universo matemático: el cálculo diferencial y el cálculo integral. El instrumento ideal para entender y explicar el funcionamiento del mundo real, desde las cosas más próximas hasta el rincón más alejado del universo.
Una breve historia de las funciones
En las matemáticas actuales el concepto de función se define del modo siguiente:
Sean A y B conjuntos. Se llama función entre A y B a cualquier relación establecida entre los elementos de A y B de tal modo que a cada elemento de A le corresponde un único elemento de B.
Para representar las funciones se suele utilizar la notación 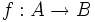 para los conjuntos,
para los conjuntos, 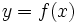 para los elementos. A se llama conjunto inicial y B es el conjunto final.
para los elementos. A se llama conjunto inicial y B es el conjunto final.
Se pueden definir funciones entre cualquier tipo de conjuntos, pero las más interesantes son las que se establecen entre conjuntos de números. En los próximos temas vamos a estudiar funciones definidas en el conjunto de los números reales: las funciones reales (conjunto final)
de variable real (conjunto inicial), 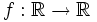 .
.
El concepto de función se desarrolló con el paso del tiempo; su significado fue cambiando y también la forma en que se definía, ganando precisión a través de los años.
Comenzaremos en Mesopotamia. En las matemáticas babilónicas encontramos tablas con los cuadrados, los cubos y los inversos de los
números naturales. Estas tablas sin duda definen funciones de 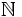 en o de en
en o de en 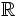 , lo que no implica que los babilonios conocieran el concepto de función. Conocían y
manejaban funciones específicas, pero no el concepto abstracto y moderno de función.
, lo que no implica que los babilonios conocieran el concepto de función. Conocían y
manejaban funciones específicas, pero no el concepto abstracto y moderno de función.

En la Grecia clásica también manejaron funciones particulares —incluso en un sentido moderno de relación entre los elementos de dos conjuntos y no sólo de fórmula— pero es poco probable que comprendieran el concepto abstracto moderno de función.

En la revolución científica iniciada en el siglo XVI los científicos centraron su atención en los fenómenos de la naturaleza, poniendo énfasis en las relaciones entre las variables que determinaban dichos fenómenos y que podían ser expresadas en términos matemáticos. Era necesario comparar las variables, relacionarlas, expresarlas mediante números y representarlas en algún sistema geométrico adecuado.
Galileo Galilei (1564-1642) pareció entender el concepto de función aún con mayor claridad. Sus estudios sobre el movimiento contienen la clara comprensión de una relación entre variables.
Casi al mismo tiempo que Galileo llegaba a estas ideas, Renè Descartes (1596-1650) introducía la geometría analítica. Descartes desarrolló y llevó a sus fundamentales consecuencias las ideas que siglos atrás se habían usado para representar en el plano relaciones entre magnitudes. Ahora cualquier curva del plano podía ser expresada en términos de ecuaciones y cualquier ecuación que relacionara dos variables podía ser representada geométricamente en un plano.
Los matemáticos de la antigüedad, así como los matemáticos de la Edad Moderna hasta fines del siglo XVII, cuando debido a los trabajos de Newton y de Leibniz fue terminada la construcción del cálculo diferencial e integral, no tenían la definición general de la función. En aquel tiempo todavía no tenían necesidad de tal definición. Si a Newton o a Leibniz le preguntasen qué es “una función en general”, la respuesta, por lo visto, sería que “una función en general” es el resultado de ciertas operaciones (algebraicas o transcendentes elementales) con las variables independientes. Semejante definición apareció por primera vez en un trabajo del alumno y colaborador de Leibniz, Johan Bernoulli, en 1718. En este trabajo la función se definía como una “expresión analítica”: "una función es una cantidad formada de alguna manera a partir de cantidades indeterminadas y constantes".
El primer problema, en el que los matemáticos tuvieron la necesidad de tener una definición general de función, fue el problema de la cuerda vibrante. A este problema se dedicaban los más grandes matemáticos de los mediados del siglo XVIII D’Alembert y Euler.
En 1748, Euler entendía que una función es una curva, dibujada por un movimiento libre de la mano. Para D’Alembert, que era seguidor de la escuela de J. Bernoulli, una función era una expresión analítica. ¿Qué concepto es más amplio, cuál es más estrecho? La discusión entre D’Alembert y Euler duró varios años. En 1755, Euler, bajo la influencia de las argumentaciones de D’Alembert, dio pronto otra definición de función que es más “matemática” que la anterior en apariencia, pero no en esencia: Cuando unas cantidades dependen de otras de tal forma que al variar las últimas también varían las primeras, entonces las primeras se llaman funciones de las segundas. Esta nueva definición contiene tanto la definición de D’Alembert, como la anterior definición “mecánica” del mismo Euler.
Al mismo tiempo, puesto que en ella no se habla nada sobre la naturaleza permisible de la dependencia de las primeras cantidades de las segundas, la definición sigue siendo bastante difusa, así que cada uno de los posteriores matemáticos del siglo XVIII tenía libertad para interpretarla a su manera. En el gran curso de cálculo diferencial e integral, escrito por La Croix para la Escuela Politécnica de París (1797), está aceptada de hecho esta misma definición. Adicionalmente está introducida una indicación para decir que la naturaleza de la dependencia puede no ser conocida de antemano. S. La Croix, en 1797, da esta definición: Cualquier cantidad, cuyo valor depende de una o de otras varias cantidades, se llama función de estas últimas, independientemente de si se conocen o no las operaciones que hay que realizar para pasar de éstas a la primera.

Dirichlet, en 1837, da una definición satisfactoria del concepto de función: y es función de x, si a cada valor de x le corresponde un valor completamente determinado de la y; además no es importante el método con el que ha sido establecida la correspondencia señalada.
Lobachevski, en 1934: Una función de x es un número que se da a cada x y que varía constantemente con la x. El valor de la función puede estar dado o por una expresión analítica o por una condición que da el procedimiento para probar todos los números. La dependencia puede existir y quedarse desconocida.
Los matemáticos del siglo XIX suponían que los límites del desarrollo del análisis matemático habían sido establecidos por la definición de Dirichlet de una vez y para siempre. Pero a finales del siglo, los matemáticos constataron con sorpresa que la definición de Dirichlet, que parecía indiscutiblemente clara y precisa, contiene en sí inesperadas dificultades de principio, serias hasta tal punto, que muchos empezaron a negarse a admitir en ella algún sentido. Para aclarar esta cuestión, comparemos la definición de Lobachevski y la definición de Dirichlet aplicándolas al objeto siguiente. Supongamos que a cada número natural n=1,2,... le corresponde el número a(n) que es igual a 1, si en el desarrollo decimal del número pi hay n nueves seguidos; y es igual a cero en el caso contrario. ¿Se trata de una función de n o no? Dirichlet diría: “Está claro que esto es una función. Para cada n, o existen n nueves seguidos en el desarrollo del número pi, o no existen; la tercera posibilidad se excluye. Puesto que no impongo condiciones a la naturaleza de la dependencia, ante mí hay efectivamente una función definida con exactitud”. Lobachevski diría: “No conozco la regla que da para cada n la posibilidad de saber si en el desarrollo del número pi hay n nueves seguidos. Puede ser que esta regla no exista. Por consiguiente aquí no hay función”.
Los matemáticos se dividieron en dos tendencias: los partidarios de la definición de función “según Dirichlet”, que no exigían una regla obligatoria; y los partidarios de la definición de función “según Lobachevski”, que exigían una regla obligatoria, formada por un número finito de palabras. Los representantes de la segunda corriente, llamados intuicionistas, renunciaban a la mayor parte de análisis clásico y formaban la matemática intuicionista propia. Los representantes de la primera corriente, que no deseaban renunciar a los logros del análisis clásico, se resignaron a aceptar la existencia de muchos hechos paradójicos, que resultaban de la existencia de las funciones sin regla.
Actualmente se puede constatar que el posterior desarrollo de las matemáticas no había seguido el camino de los intuicionistas y al fin de cuentas los logros del análisis clásico se quedaron firmes.Sin embargo algunos resultados concretos de los intuicionistas encontraron en nuestros tiempos una aplicación inesperada en la teoría de las computadoras. El tratamiento informático solo pueden tener funciones que se definen mediante reglas con una cantidad finita de palabras y además esta cantidad tiene que ser relativamente pequeña.
Historia de las funciones (Parte 1)
Historia de las funciones (Parte 2)
Las funciones describen fenómenos reales
Escala de Richter


La escala sismológica de Richter, también conocida como escala de magnitud local (ML), es una escala logarítmica arbitraria que asigna un número para cuantificar la energía que libera un terremoto, denominada así en honor del sismólogo estadounidense Charles Francis Richter (1900-1985).
La sismología mundial usa esta escala para determinar la fuerza de seismos de una magnitud entre 2,0 y 6,9 y de 0 a 400 kilómetros de profundidad. Aunque los medios de comunicación suelen confundir las escalas, para referirse a eventos telúricos actuales se considera incorrecto decir que un seismo «fue de magnitud superior a 7,0 en la escala de Richter», pues los seismos con magnitud superior a 6,9 se miden desde 1978 con la escala sismológica de magnitud de momento, por tratarse esta última de una escala que discrimina mejor en los valores extremos.
Fue desarrollada por Charles Francis Richter con la colaboración de Beno Gutenberg en 1935, ambos investigadores del Instituto de Tecnología de California, con el propósito original de separar el gran número de terremotos pequeños de los menos frecuentes terremotos mayores observados en California en su tiempo. La escala fue desarrollada para estudiar únicamente aquellos terremotos ocurridos dentro de un área particular del sur de California cuyos sismogramas hubieran sido recogidos exclusivamente por el sismómetro de torsión de Wood-Anderson.
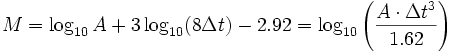
donde:
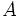 = amplitud de las ondas en milímetros, tomada directamente en el sismograma.
= amplitud de las ondas en milímetros, tomada directamente en el sismograma.
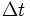 = tiempo en segundos desde el inicio de las ondas P (Primarias) al de las ondas S (Secundarias).
= tiempo en segundos desde el inicio de las ondas P (Primarias) al de las ondas S (Secundarias).
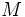 = magnitud arbitraria pero constante a terremotos que liberan la misma cantidad de energía.
= magnitud arbitraria pero constante a terremotos que liberan la misma cantidad de energía.
El uso del logaritmo en la escala es para reflejar la energía que se desprende en un terremoto. Una escala logarítmica hace que los valores asignados a cada nivel aumenten de forma logarítmica, y no de forma lineal. Esto significa que un terremoto de magnitud 6 es 10 veces más potente que uno de magnitud 5. Richter tomó la idea del uso de logaritmos en la escala de magnitud estelar, usada en astronomía para describir el brillo de las estrellas y de otros objetos celestes.
Magnitud aparente de un objeto celeste

La magnitud aparente (m) de un objeto celeste es un número que indica la medida de su brillo tal y como es visto por un observador desde la Tierra y la cantidad de luz (energía) que se recibe del objeto. Mientras que la cantidad de luz recibida depende realmente del ancho de la atmósfera, las magnitudes aparentes se normalizan a un valor que tendrían fuera de la atmósfera. Cuanto menor sea el número, más brillante aparece una estrella. El Sol, con magnitud aparente de −27, es el objeto más brillante en el cielo. Se ajusta al valor que tendría en ausencia de la atmósfera. Cuanto más brillante aparece un objeto, menor es su valor de magnitud (es decir, la relación inversa). Además, la escala de magnitudes es logarítmica: una diferencia de una magnitud corresponde a un cambio en el brillo de un factor alrededor de 2,512.
Generalmente, se utiliza el espectro visible (vmag) como base para la magnitud aparente. Sin embargo, se utilizan también otros espectros (por ejemplo, la banda J del infrarrojo cercano). En el espectro visible, Sirio es la estrella más brillante después del Sol. En la banda-J del infrarrojo cercano, Betelgeuse es la más brillante. La magnitud aparente de las estrellas se mide con un bolómetro.
La magnitud aparente puede medirse para determinadas bandas del espectro luminoso. En el caso del espectro visible, se denomina magnitud visual (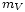 ) y puede ser estimada por el ojo humano.
) y puede ser estimada por el ojo humano.
Actualmente se utilizan los fotómetros que permiten medir magnitudes con mucha precisión. Éste es capaz de catalogar en orden de magnitud aparente y distinguir cuando dos estrellas tienen la misma magnitud aparente o una estrella y una fuente artificial.
La escala con la que se mide la magnitud, tiene su origen en la práctica helenística de dividir las estrellas visibles con ojo desnudo en seis magnitudes. Las estrellas más visibles a simple vista fueron pensadas para formar parte de la primera magnitud (m = +1), mientras que las más débiles eran consideradas como sexta magnitud (m = +6), el límite del ojo humano (sin ayuda de un telescopio). Este método, algo primitivo, para indicar la visibilidad de las estrellas a simple vista fue divulgado por Ptolomeo en su Almagesto, y se cree que pudo haber sido originado por Hiparco de Nicea. Este sistema original no medía la magnitud del Sol. Debido al hecho de que la respuesta del ojo humano a la luz es logarítmica la escala que resulta es también logarítmica.
En 1856 Norman Pogson formalizó el sistema definiendo que una típica estrella de primera magnitud es aquella 100 veces más visible que una típica estrella de magnitud sexta; así, una estrella de primera magnitud es aproximadamente 2.512 veces más visible que una de segunda magnitud. La raíz quinta de 100, aprox. 2.512, se conoce como cociente de Pogson. La escala de Pogson se fijó originalmente asignando a la estrella Polaris la magnitud de 2. Pero dado que los astrónomos han descubierto que la estrella polar es levemente variable, ahora se utiliza la estrella Vega como referencia.
El sistema moderno no se limita a 6 magnitudes. Los objetos realmente visibles tienen magnitudes negativas. Por ejemplo Sirius, la estrella más visible, tiene una magnitud aparente de -1.44 a -1.46. La escala moderna incluye a la Luna y al Sol; la Luna tiene una magnitud aparente de -12.6 y el Sol tiene una magnitud aparente de -26.7. Los telescopios Hubble y Keck han localizado estrellas con magnitudes de +30.
La magnitud aparente en la banda x se puede definir como:
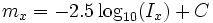
donde 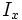 es el flujo luminoso observado en la banda
es el flujo luminoso observado en la banda 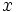 , y
, y 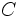 es una constante que depende de las unidades de flujo y de la banda.
es una constante que depende de las unidades de flujo y de la banda.
Desintegración radioactiva

Las partículas alfa (núcleos de helio) se detienen al interponer una hoja de papel. Las partículas beta (electrones y positrones) no pueden atravesar una capa de aluminio. Sin embargo, los rayos gamma (fotones de alta energía) necesitan una barrera mucho más gruesa, y los más energéticos pueden atravesar el plomo.
La radiactividad o radioactividad es un fenómeno físico por el cual los núcleos de algunos elementos químicos, llamados radiactivos, emiten radiaciones que tienen la propiedad de impresionar placas radiográficas, ionizar gases, producir fluorescencia, atravesar cuerpos opacos a la luz ordinaria, entre otros. Debido a esa capacidad, se les suele denominar radiaciones ionizantes (en contraste con las no ionizantes). Las radiaciones emitidas pueden ser electromagnéticas, en forma de rayos X o rayos gamma, o bien corpusculares, como pueden ser núcleos de helio, electrones o positrones, protones u otras. En resumen, es un fenómeno que ocurre en los núcleos de ciertos elementos inestables, que son capaces de transformarse o decaer, espontáneamente, en núcleos atómicos de otros elementos más estables. Así un isótopo pesado puede terminar convirtiéndose en uno mucho más ligero, como el uranio que, con el transcurrir de los siglos, acaba convirtiéndose en plomo.
La radiactividad se aprovecha para la obtención de energía nuclear, se usa en medicina (radioterapia y radiodiagnóstico) y en aplicaciones industriales (medidas de espesores y densidades, entre otras).
En general son radiactivas las sustancias que no presentan un balance correcto entre protones o neutrones. Cuando el número de neutrones es excesivo o demasiado pequeño respecto al número de protones, se hace más difícil que la fuerza nuclear fuerte debido al efecto del intercambio de piones pueda mantenerlos unidos. Finalmente, el desequilibrio se corrige mediante la liberación del exceso de neutrones o protones, en forma de partículas α que son realmente núcleos de helio, y partículas β, que pueden ser electrones o positrones. Estas emisiones llevan a dos tipos de radiactividad:
- Radiación α, que aligera los núcleos atómicos en 4 unidades másicas, y cambia el número atómico en dos unidades.
- Radiación β, que no cambia la masa del núcleo, ya que implica la conversión de un protón en un neutrón o viceversa, y cambia el número atómico en una sola unidad (positiva o negativa, según si la partícula emitida es un electrón o un positrón).
Un tercer tipo de radiación, la radiación γ, se debe a que el núcleo pasa de un estado excitado de mayor energía a otro de menor energía, que puede seguir siendo inestable y dar lugar a la emisión de más radiación de tipo α, β o γ. La radiación γ es, por tanto, un tipo de radiación electromagnética muy penetrante, ya que tiene una alta energía por fotón emitido.

La desintegración radiactiva se comporta en función de la ley de decaimiento exponencial:
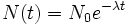
donde:
-
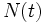 es el número de radioisótopos o radionúclidos existentes en un instante de tiempo t.
es el número de radioisótopos o radionúclidos existentes en un instante de tiempo t.
-
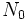 es el número de radioisótopos existentes en el instante inicial t = 0.
es el número de radioisótopos existentes en el instante inicial t = 0.
-
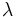 , llamada constante de desintegración radiactiva, es la probabilidad de desintegración por unidad de tiempo. La constante de desintegración es el cociente entre el número de desintegraciones por segundo y el número de átomos radiactivos (
, llamada constante de desintegración radiactiva, es la probabilidad de desintegración por unidad de tiempo. La constante de desintegración es el cociente entre el número de desintegraciones por segundo y el número de átomos radiactivos (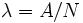 ).
).
Se llama tiempo de vida o tiempo de vida media de un radioisótopo el tiempo promedio de vida de un átomo radiactivo antes de desintegrarse. Es igual a la inversa de la constante de desintegración radiactiva ( ).
).
Al tiempo que transcurre hasta que la cantidad de núcleos radiactivos de un isótopo radiactivo se reduzca a la mitad de la cantidad inicial se le conoce como periodo de semidesintegración, período, semiperiodo, semivida o vida media (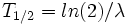 ). Al final de cada período, la radiactividad se reduce a la mitad de la radiactividad inicial. Cada radioisótopo tiene un semiperiodo característico, en general diferente del de otros isótopos.
). Al final de cada período, la radiactividad se reduce a la mitad de la radiactividad inicial. Cada radioisótopo tiene un semiperiodo característico, en general diferente del de otros isótopos.
El periodo de semidesintegración del uranio-238 es aproximadamente 4.470 millones de años y el del uranio-235 es 704 millones de años,3 lo que los convierte en útiles para estimar la edad de la Tierra.

